はじめまして。Logbiiのヤンと申します。
Logbiiの技術ブログでは、最近の技術動向についてや、社内で扱っている技術などについて紹介していきます。主に、機械学習・ディープラーニングに関する論文の紹介や実装などを中心にしていく予定です。
初回のテーマとしては、画像認識の自動運転への応用にフォーカスして紹介していきます。
物体認識アルゴリズムの有名なものとしてはSSD[1]、YOLO[2]などがあります。今年の4月には、処理速度が向上したYOLOv3[3]が発表されるなど、アルゴリズムは常に進化しています。
アルゴリズムとしてパフォーマンスを出すのは重要です。実用化、例えば自動運転の物体認識を考えると、エッジ側での効率的な計算、周囲画像の取得方法、小さな標識の認識なども考えないといけないです。実用化の場合には、アルゴリズム、利用シーンと分析シナリオをケースバイケースで考える必要があると思います。
最近、各大手企業はエッジコンピューティングをアピールする傾向になりました。(海外ではNVIDIA[4]、Microsoft[5]、日本では三菱電機[6]、NEC[7]、富士通[8]など)。ディープラーニングを活用した画像認識は2012年のAlexNet[9]以来、精度は毎年向上しています。最近のトレンドとしては、効率よくエッジ端末で処理するため、精度とパフォーマンスのバランスが重視されているように感じます。
今回は、画像認識の自動運転での応用研究の中で、エッジ側でのディープラーニングの利用を想定したDEEPEYE[10]という論文をピックアップして紹介します。
DEEPEYEの概要
これまで物体認識の学習と分析には多くのパラメータ、データの入力が必要なため、エッジ側(Terminal Device)でリアルタイムで使用するには、パフォーマンス面の課題がありました。著者は8bitの量子化(Quantization)を用いてYOLOを圧縮し訓練して、テンソル化(Tensorized)して圧縮したRNNを合わせて、従来のYOLOと比べて約1/4にモデル容量を圧縮し、通常のRecurrent Neural Network(RNN)を用いた場合と比べて2.87倍のスビートアップ、約1万5千分の1のパラメータの減少を達成しました。
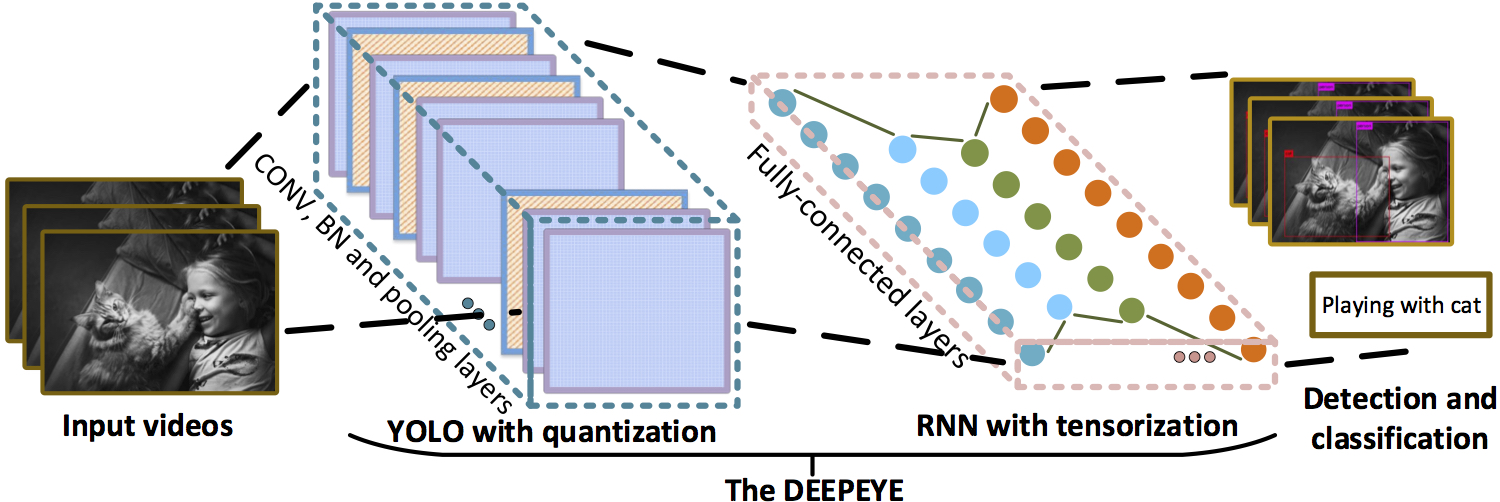
[10]より引用
著者はこの方法をDEEPEYEと命名しています。モデルのフレームワークはQ-YOLO(8 bit量子化:Quantizationで訓練したYOLO)とT-RNN(テンソルして圧縮化したRNN)を合わせて、画像に写った物を分類して行動をタグ付けします。(上図でのタグは”Playing with cat”) 。下図では上から、“Balancing”、“Cleaning”、“Fighting”というタグがつけられています。

[10]より引用
YOLOの量子化(Q-YOLO)
Q-YOLOで用いられる量子化とは、浮動小数点で表現される重みなどのパラメータを、8bitで表現する手法です。TensorFlowなどに実装されています[11]。
量子化のメリットとしては、以下のような点があげられます。
1、 ディスクリソースの削減
2、 計算リソースの削減と消費電力の削減
重みパラメータを量子化するイメージを下図に示します。重みパラメータを小数点の形ではなく8-Bitに変換します。例えば、PS4(64Bit)ゲームをファミコン(8Bit)に変換するような感じです。Q-YOLOでは、畳込みレイヤー(convolutional layers)、バッチ正規化レイヤー(batch normalization)、max-poolingレイヤーの重みを8Bit(-127)〜(+127)として量子化し、特徴マップ(Feature Map)は0〜255として量子化しています。
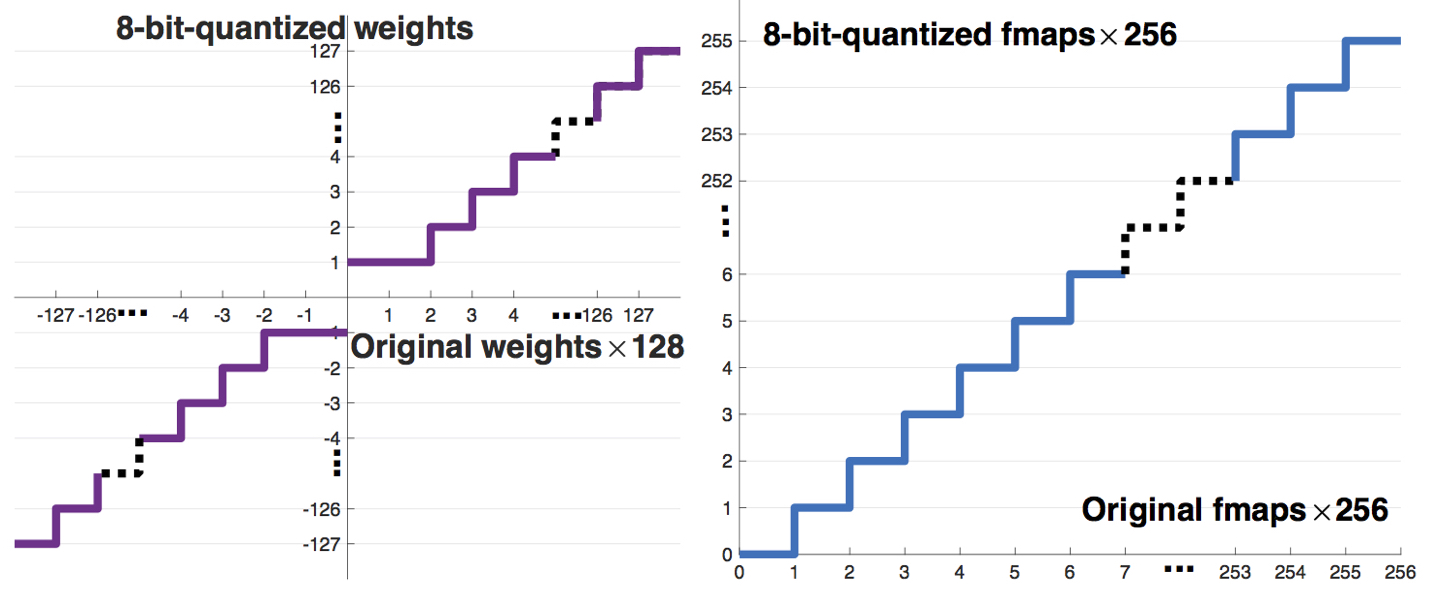
[10]より引用
T-RNNの評価
T-RNNの評価では、訓練データとしてUCF11[12]を使っています。
下図では、T-RNN (入力:Q-YOLOのアウトプット)、T-RNN (入力:動画フレーム)、通常の RNN(入力:動画フレーム)の3つのケースでLossとAccuracyを比較しています。epoch20を超えると最初のケースが精度が一番高くなっており、ピークの精度では通常のRNNよりも16.58%良い結果となりました。
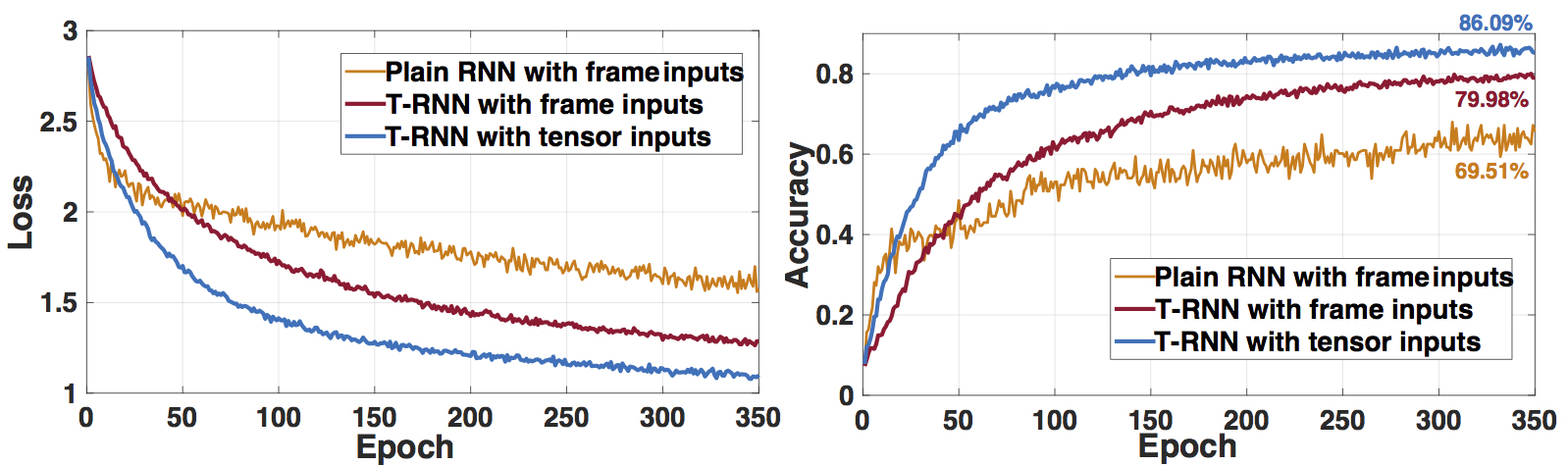
[10]より引用
パフォーマンス比較
下の表では、通常のRNN(入力:動画フレーム)、T-RNN(入力:動画フレーム)、DEEPEYE(入力:Q-YOLOアウトプット+T-RNN)について、精度、パラメータ数、圧縮率、実行時間(learning epochの平均時間)とスピードについてまとめています。DEEPEYEは通常のRNNに比べて精度が高く、学習時間が削減されました。

[10]より引用
まとめ
今回の研究は、画像認識アルゴリズムの更なる精度を追求するのではなく、コンピューターリソースと実効速度などを最適化するチャレンジとなっています。今後はこういった実用化に向けた応用研究が増えていくかもしれません。
参考文献
[1] Wei Liu et al., “SSD: Single Shot MultiBox Detector”, arXiv:1512.02325, 2016
[3] Joseph Redmon et al., “YOLOv3: An Incremental Improvement”, preprint 2018
[4] https://www.nvidia.co.jp/object/nvidia-jetson-tx2-enables-ai-at-the-edge-20170313-jp.html
[5] https://www.microsoft.com/ja-jp/internet-of-things/intelligentedge
[6] http://www.mitsubishielectric.co.jp/news/2018/0419-a.html
[7] https://jpn.nec.com/techrep/journal/g17/n01/170106.html
[8] http://www.fujitsu.com/jp/services/knowledge-integration/insights/20180604-02/index.html
[11] https://www.tensorflow.org/performance/quantization